人生苦短, 我学 Python!
这篇文章主要记录一下我学习 Python 爬虫的一个小例子, 是爬取的拉勾网的数据.
1.准备
配置 Python 环境什么的就不说了, 网上教程很多, 自行解决.
2.扒源码
先打开[拉勾网][1]的网页. 我们要爬取这部分的数据, 即搜索结果列表数据:
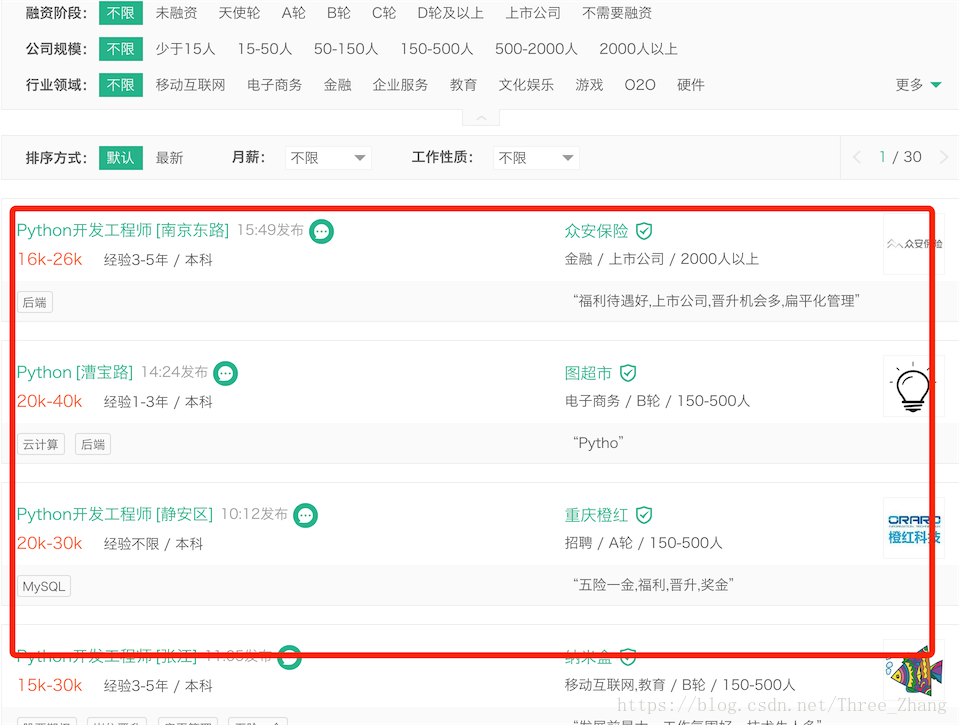
检查源码, 打开如下图所示位置:
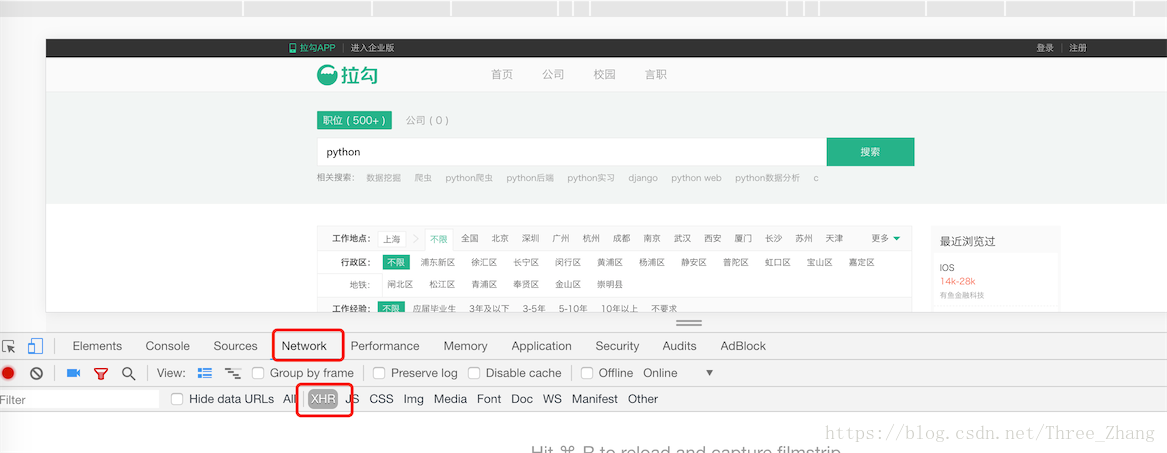
然后发现,这部分数据是我们所要爬取的数据:
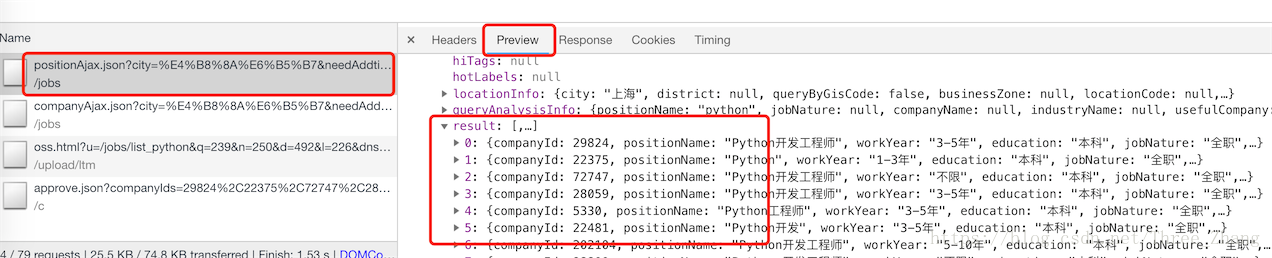
ok! 开始撸代码!
1 | import requests |
解释一下:
headers的获取: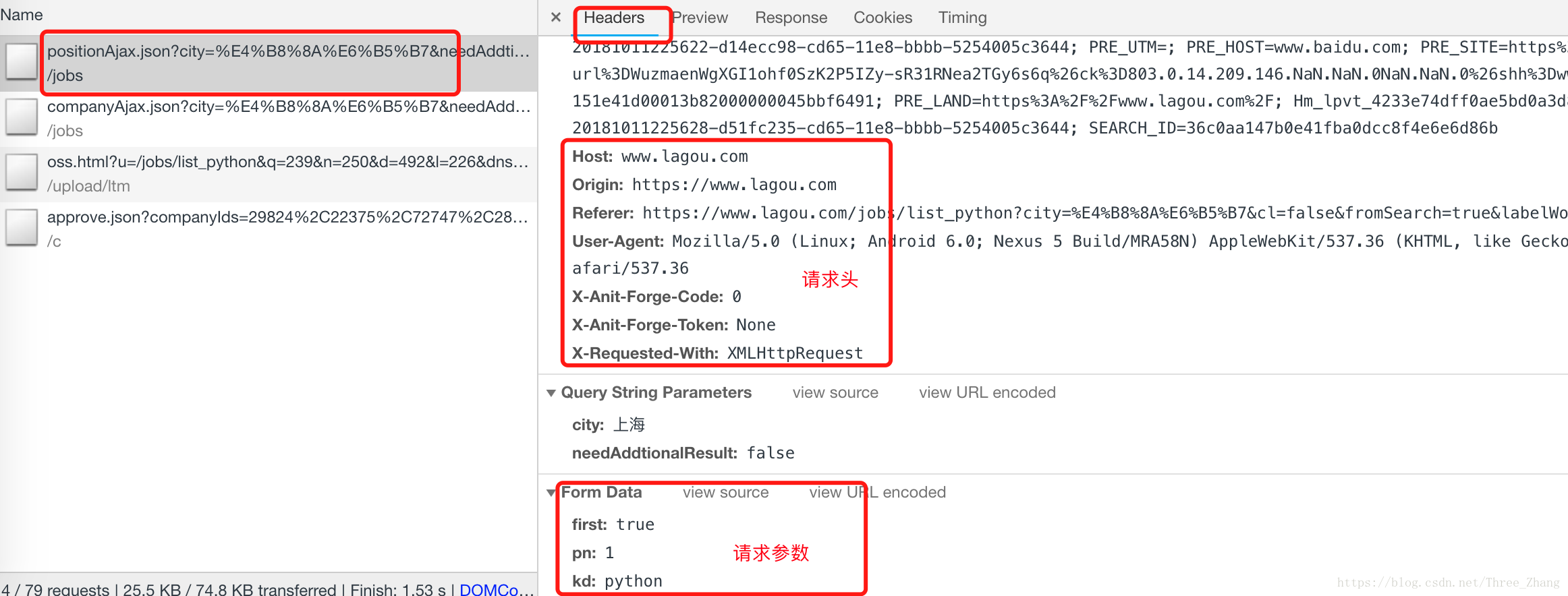
这样就能获取到列表数据了, 为了方便操作这些数据, 还可以转换成 json 格式, 这样就可以为所欲为了!
enjoy it!

